
NASA Harvest Tutorial on Agricultural-Focused Machine Learning Modeling
Members of the NASA Harvest consortium attended the 2022 Conference on Computer Vision and Pattern Recognition (CVPR) and presented a tutorial for conference attendees on the use of remote sensing data to map and monitor global agricultural conditions. Tutorial participants were introduced to how earth observations are transforming global agriculture and how researchers are creating systems that use machine learning and computer vision with earth observations for monitoring agriculture and food security. Attendees also participated in a hands-on session where they got to practice training and evaluating machine learning models and use their model to produce a cropland classification map.

Hannah Kerner, Catherine Nakalembe, and Ivan Zvonkov at CVPR 2022
CVPR, an annual conference first hosted in 1983, is regarded as one of the top meetings in the field of computer vision pattern recognition. Presenters undergo a selective paper review process to showcase their research. NASA Harvest was represented by Dr. Hannah Kerner, Harvest’s AI lead; Dr. Catherine Nakalembe, Harvest’s Africa Program lead; and Ivan Zvonkov, Harvest machine learning engineer.
Use of Remote Sensing in Agriculture
Remote sensing techniques have been critical in revolutionizing agricultural monitoring and management. These changes have been especially helpful in the context of a growing global population and the pressure created from climate change and its impacts on global growing conditions. Food insecurity is a major global concern with 9.8% of Earth’s population undernourished in 2020 and one-third lacking access to adequate food.
Kerner introduced tutorial participants to the fundamentals and nuances of remote sensing data. Most participants had experience with various machine learning and AI concepts, but limited experience with earth observation data,. Comparing the spatial resolution of Earth observation data to image datasets used in other computer vision applications like autonomous vehicles, Kerner noted the importance of matching analysis scale to the resolution of available imagery and the difficulties of turning remote sensing datasets into “machine learning-ready” datasets. Kerner also spoke to the importance of temporal resolution and the value of high-repeat sensors that are able to acquire images more frequently, which allows finer-scale changes to be observed over time. Finally, tutorial attendees learned about spectral resolution and the differences between optical, thermal, and radar imagery and the benefits and considerations of each.
Equipped with this understanding of remote sensing participants then learned from Nakalembe about use cases of how farmers and policymakers are using remote sensing data to inform management decisions. Farmers are able to use remote sensing data to better understand important variables like temperature, precipitation, and soil moisture - both in the current day and patterns over previous years. Given the relationship between precipitation and agricultural drought, giving farmers the knowledge that they should delay planting by even a week can be tremendously helpful to the eventual yield of their crops.
Policymakers in food insecure countries are able to use global crop monitors to anticipate potential food shortages not just in their own country, but in major exporting countries as well, giving them more time to prepare for shortfalls and avoid last minute price hikes.

Slides from Catherine Nakalembe’s presentation at the 2022 CVPR conference. The first slide shows North American anomalies in NDVI, an EO Data-derived variable often used as an indicator for crop condition. With the invasion of Ukraine and Covid-19 straining global cereals, monitoring the health of crops in other major exporting countries is vital in ensuring global supply. The second slide looks at how NDVI changes throughout the year within Kenya, a country struggling with drought over the last several years. The third slide looks at the economic benefits of identifying cropland and monitoring crop conditions throughout the growing season. Reduced lag times in ag-related disaster response allows policymakers to also reduce associated hits to GDP, resulting in large financial savings.
Machine Learning for Agriculture
Kerner then talked about how the NASA Harvest Consortium is utilizing machine learning in various Earth observation-derived models. Given CVPR’s focus on AI and machine learning, many workshop attendees were familiar with the underlying techniques of many of these models, but were able to explore how they have been specially applied for agricultural monitoring.
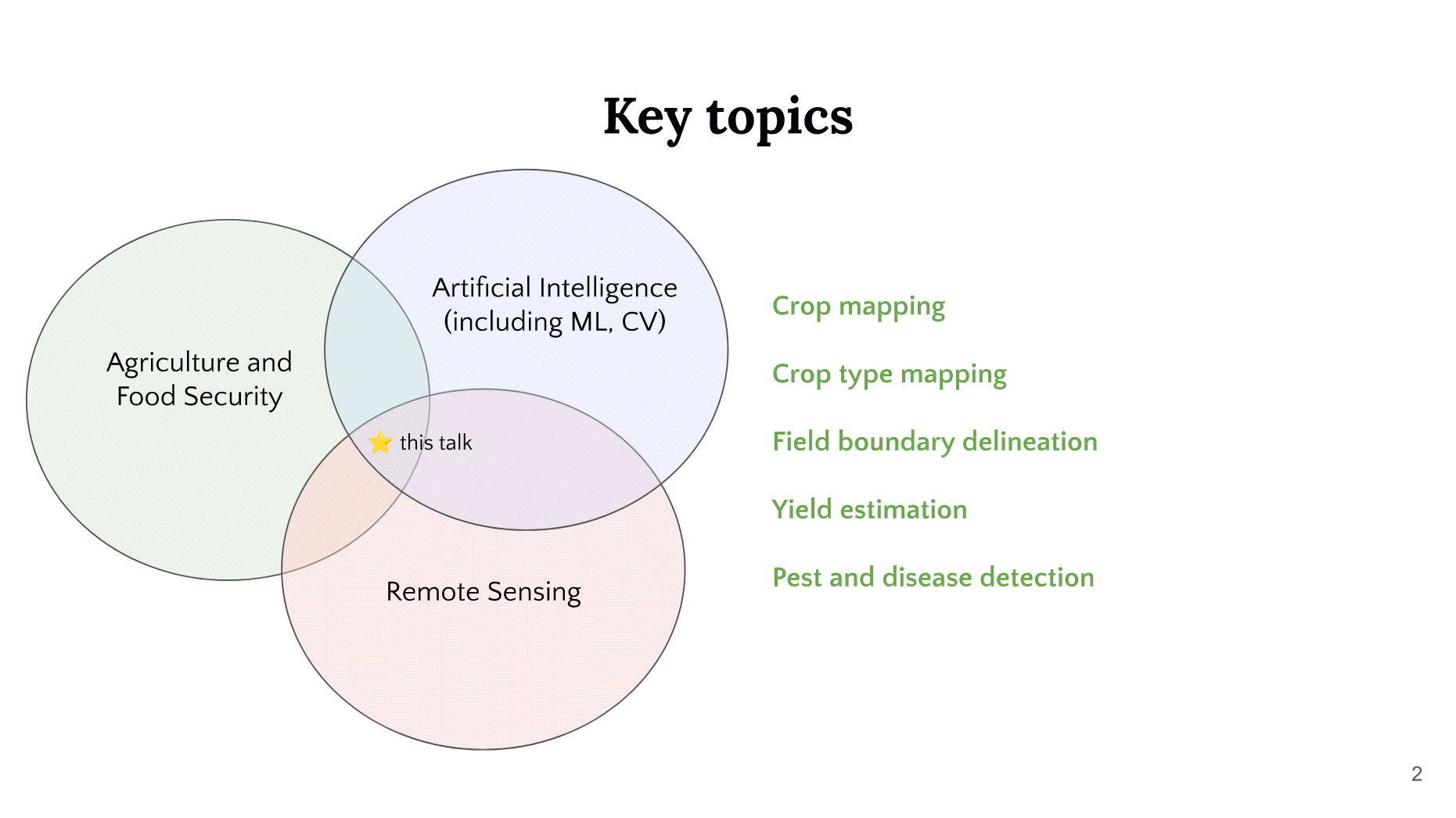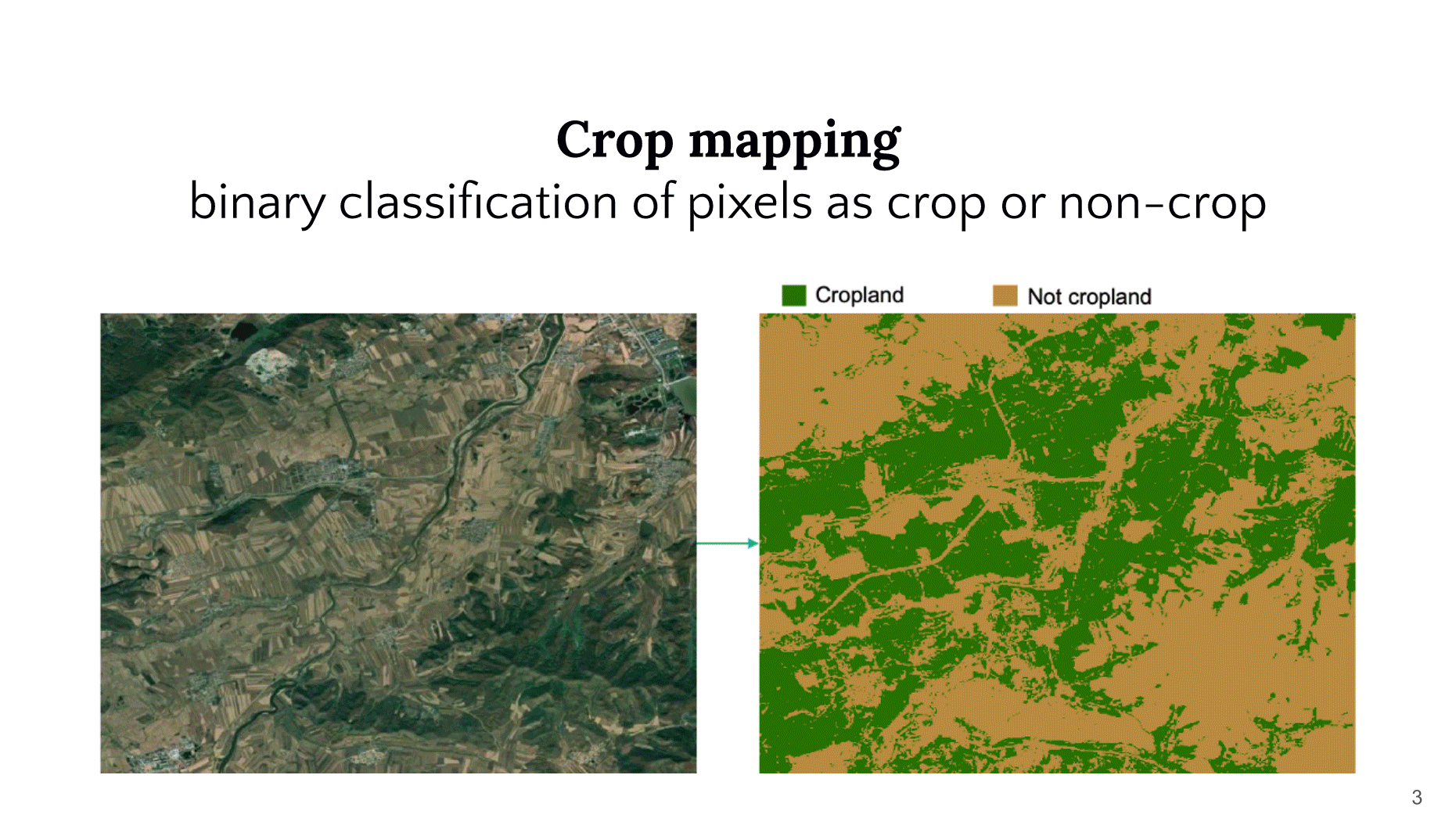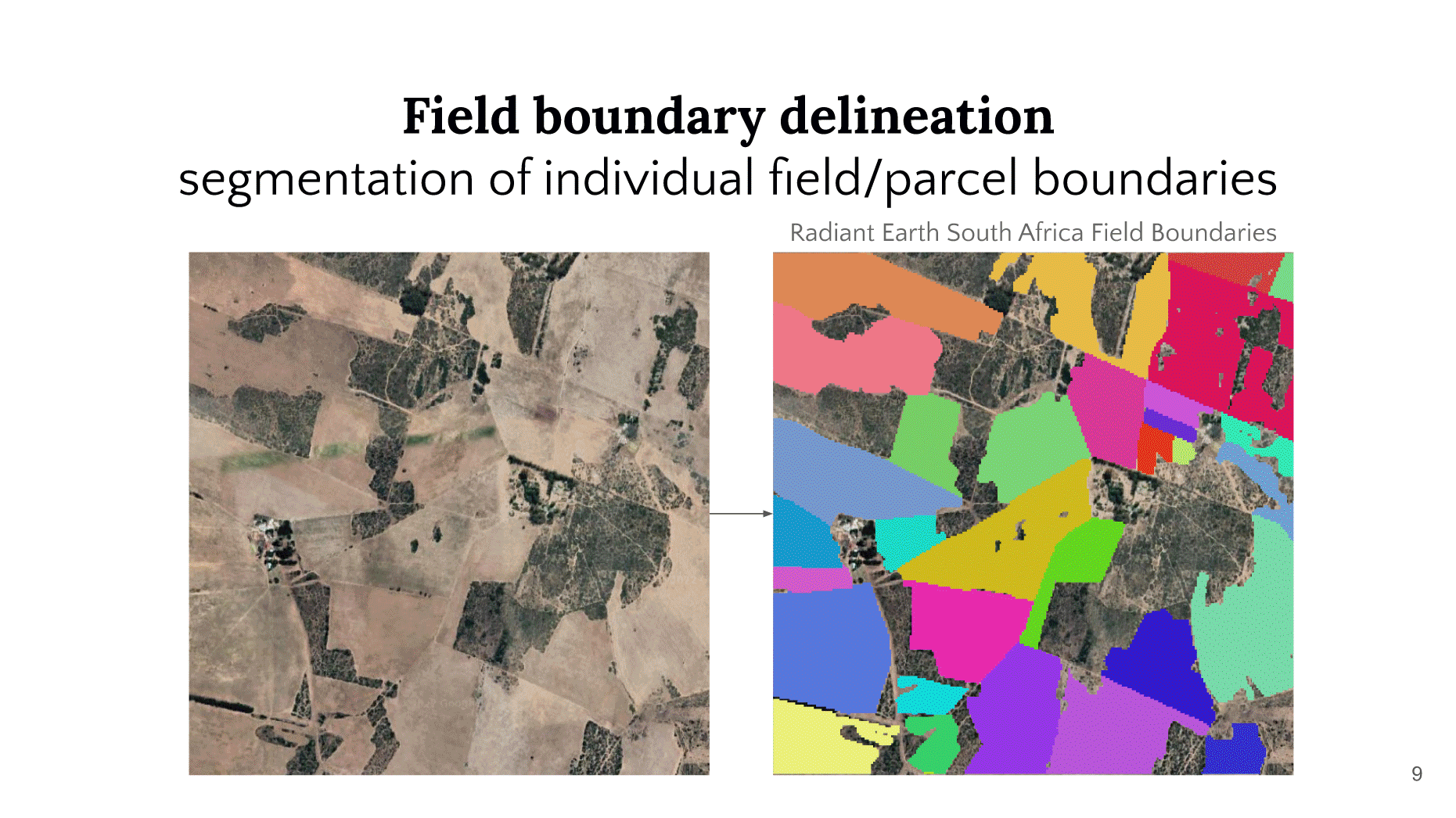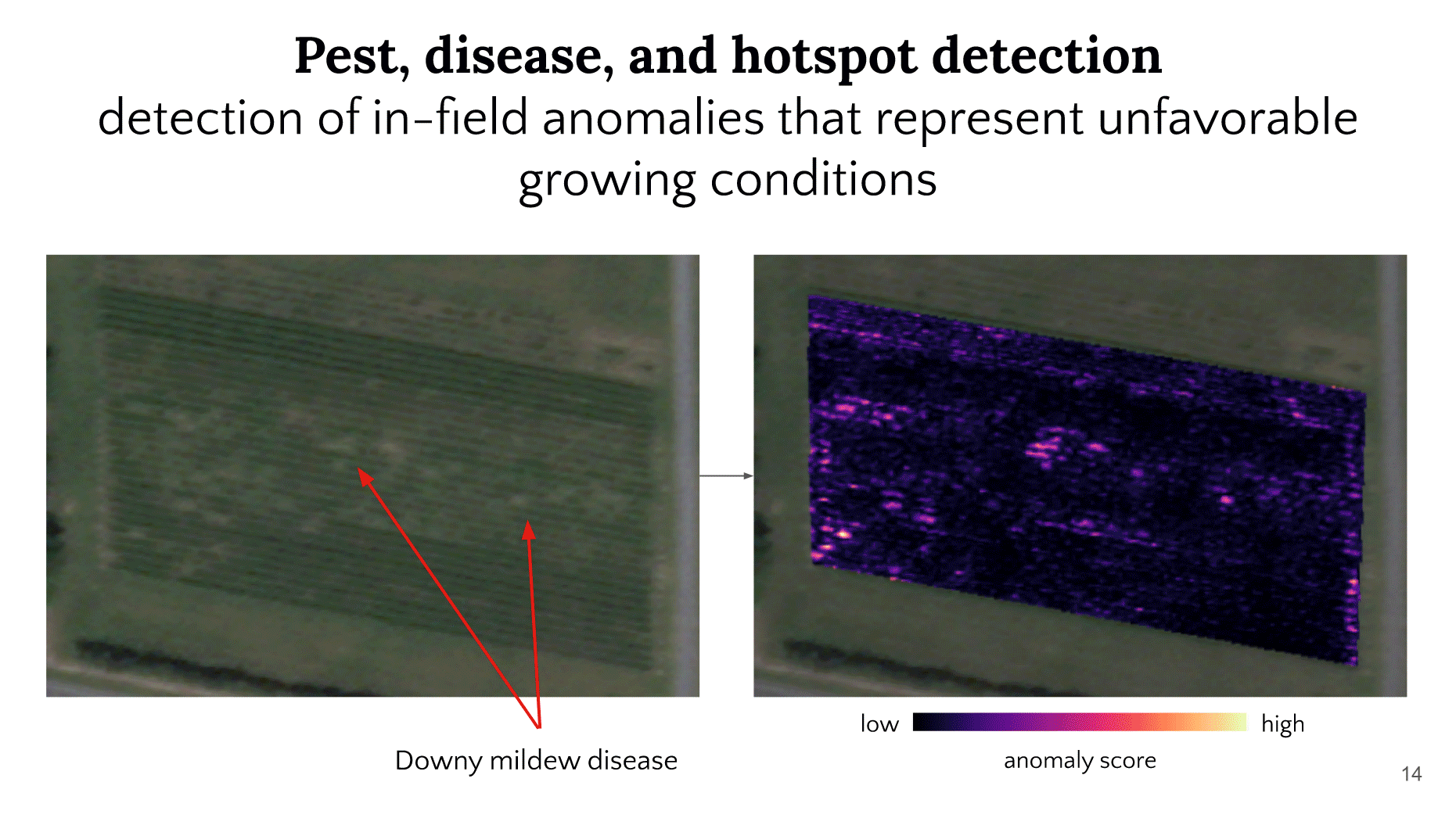
Slides from Hannah Kerner’s presentation listing common machine learning agricultural applications.
For instance, crop mapping models are binary classification models at their core. For agricultural monitoring, researchers train these models to determine if individual pixels in satellite images are crop or non-crop, often across very large spatial scales. Kerner’s group has created a methodology for rapid mapping of cropland at large scales in short timeframes that was first used when helping Togo respond to uncertainties around harvests in the early days of the COVID-19 pandemic. The method was able to map all cropland in the country within 10 days. NASA Harvest also works with crop type mapping models, a specific instance of multi-class classification, wherein pixels within an image are determined to be one of a set of crop types, e.g. wheat, maize, soybean, rice, etc.
Harvest is also working in the field of image segmentation. Our partners at the Stanford University’s Center on Food Security and the Environment have been expanding work on field boundary delineation, or the segmentation of individual field or parcel boundaries. Recent work published by the Center used deep transfer learning methods and high resolution Earth observation imagery to map over 10,000 fields in India.
Kerner described at how regression models are being used to create yield models with satellite imagery, ground data, and management practice inputs. Harvest partners recently published almost 20 years of maize yield maps across the US Midwest, allowing for analysis of the impact of drought on crop productivity in the region over the two decades. Finally, Kerner introduced an outlier detection system developed by her team which has been used for pest and crop disease identification. The model, Domain-Agnostic Outlier Ranking Algorithm or DORA, is being used in a variety of fields from volcanic activity detection to crop disease pinpointing.
Labeled Dataset for Crop Mapping Models
Nakalembe also taught workshop participants about the importance of labeled datasets for training and evaluating earth observation machine learning models; some of the difficulties in acquiring quality labeled datasets; and how NASA Harvest is creating new open access training datasets.
Labeled datasets are crucial inputs in machine learning models. For agricultural applications, labels indicating the presence or absence, or type, of crop at a given location are used to classify pixels in remotely sensed images and create cropland maps. Despite this importance, there are multiple challenges in acquiring this data. Common methods of collection include manually traveling to fields and noting the location and types of crops. This obviously has large labor and financial costs and can be hampered by poor travel conditions and weather. In addition, as land cover and land use change from year to year (and multiple times within a year for agricultural land), labels collected in one year can only be considered valid for satellite data acquired in that same year.
One alternative is to use high resolution satellite imagery to mark the locations of objects of interest. However, this requires very high resolution imagery to accurately identify often small scale features and is not sufficient for determining the type of crop growing in a field or other more nuanced characteristics than land cover type.
Due to these barriers, a lot of effort has gone into conducting field data collection operations. Nakalembe, with funding from the Lacuna Fund, an organization who provides support for machine learning projects focusing on low- and middle-income countries, has implemented an innovative field labeling project called Helmets Labeling Crops. The project will use cameras mounted on vehicles and the helmets of motorcyclists to collect ground-truth images of crops growing on the sides of roads as drivers travel. These images are then translated into geo-referenced ground-truth labels of crop type using a pipieline the Harvest ML team is developing called Street2Sat. Street2Sat uses computer vision techniques to localize specific crops in the roadside images and compute their distance away from the camera. This pipeline will provide large amounts of training data for future cropland mapping and other mapping efforts in Africa and worldwide.
Tutorial: OpenMapFlow Python Package
Zvonkov spent the final 90 minutes of the workshop walking participants through the use and different applications of the group’s novel mapping Python package, OpenMapFlow. The audience learned about the complexities of gathering training data for crop mapping models, specifically the high financial and labor costs of collecting ground truth data. This problem is particularly pronounced in areas with higher levels of food insecurity, which often have intense need for accurate mapping while lacking the resources to do so. While there is a large amount of open access cropland training data available to researchers, it is often clustered in areas that are more easily accessible, creating a data gap in the areas that need it the most. In addition, most models for classifying crops and other land cover/land use types in satellite data are not easily scalable to efficiently generate maps of predictions over large geographic areas.
OpenMapFlow was designed to address this by providing tools for efficiently processing satellite data, training machine learning models, and then using those trained models to produce maps of model predictions. The library allows users to use their own labels to train any time series model implemented in pytorch and automatically generate a map of predictions in an area and time period of interest.

Components of OpenMapFlow taken from Ivan Zvonkov’s 2022 CVPR presentation.
OpenMapFlow does this in 3 main components, each of which workshop attendees were able to explore and practice alongside Zvonkov. The first, a data processing pipeline, allows users to feed in a variety of ground truth data and remotely sensed data. Users were walked through how to explore and visualize an example dataset of crop and non-crop data points, allowing them to understand the spatial distribution of the datasets and patterns that distinguish cropland areas from other land cover.
The second component trains the model and evaluates its performance. Finally, OpenMapFlow’s third component uses the trained model to efficiently make a map of predictions. Workshop attendees were each able to tune the parameters of their model and compete to train the most accurate model. In the tutorial example, Zvonkov used one of these models to generate a predicted cropland map in real time for a 1200 km2 area in Togo.
Presentation slides and recordings from the NASA Harvest tutorial are available here. Recordings are also available in this Youtube playlist. Kerner has also provided a number of resources on AI and ML with Earth observation data here.

Examples of current study sites where NASA Harvest is using the OpenMapFlow Python package.